编译
目标代码文件、可执行文件和库
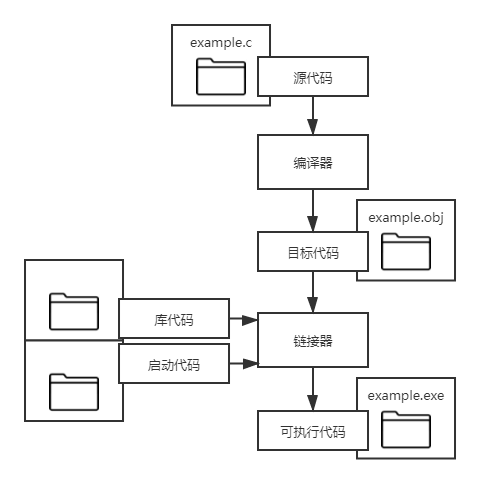
C 编程的基本策略是使用程序将源代码文件转换为可执行文件,此文件包含可以运行的机器语言代码。C 分两步完成这一工作:编译和链接。编译器将源代码转换为中间代码,链接器将此中间代码与其他代码相结合来生成可执行文件。
编译器将源代码转换成机器语言代码,将结果放置在一个目标代码文件中。虽然目标文件包含机器语言代码,但是该文件还不能运行。
目标代码文件中所缺少的第一个元素是一种叫做启动代码(start-up code)的东西,此代码相当于您的程序和操作系统之间的接口;
所缺少的第二个元素是库例程的代码。几乎所有 C 程序都利用标准 C 库中所包含的例程(称为函数)。目标代码文件不包含这一函数的代码,它包含声明使用 printf() 函数的指令。实际代码存储在另一个称为“库”的文件中。库文件中包含许多函数的目标代码。
链接器的作用是将这 3 个元素(目标代码,系统的标准启动代码,库代码)结合在一起,并将它们存放在单个文件,及可执行文件中。
Linux 编译
1
2
3
4
5
6
| #include <stdio.h>
int main(void)
{
printf("Hello World!\n");
return 1;
}
|
1
2
| gcc hello.c # 编译
a.out # 执行
|
调试
参数
gdb
file : 加载被调试的可执行程序文件
r: Run,运行被调试的程序。如果此前没有下过断点,则执行完整个程序;如果有断点,则程序暂停在第一个可用断点处
c: Continue,继续执行被调试程序,直至下一个断点或程序结束
b :
b : Breakpoint,设置断点
d [编号]: Delete breakpoint,删除指定编号的某个断点。断点编号从 1 开始递增
s: 执行一行源程序代码,如果此行代码中有函数调用,则进入该函数
n: 执行一行源程序代码,此行代码中的函数调用也一并执行
(s 相当于 “Step Info” 单步跟踪进入,n 相当于 “Step Over” 单步跟踪)
p : Print,显示指定变量的值
q: Quit,退出 GDB 调试环境
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| #include <stdio.h>
int nGlobalVar = 0;
int tempFunction(int a, int b)
{
printf("tempFunction is called, a = %d, b = %d\n", a, b);
return a + b;
}
int main(void)
{
int n;
n = 1;
n++;
n--;
nGlobalVar += 100;
nGlobalVar -= 12;
printf("n = %d, nGlobalVar = %d\n", n, nGlobalVar);
n = tempFunction(1, 2);
printf("n = %d", n);
return 0;
}
|
1
2
3
4
5
6
7
| # debug.c 源文件
# -g 编译的时候产生编译信息
# -o 指定目标文件名称
# 编译源文件
gcc -g -o debug debug.c
# debug 目标文件
gdb debug
|
转载于CSDN



